
6:50 a.m.
On Wed, May 26, 2021 at 1:25 PM Richard W.M. Jones <rjones(a)redhat.com> wrote:
On Wed, May 26, 2021 at 10:32:08AM +0100, Richard W.M. Jones wrote:
> On Wed, May 26, 2021 at 11:40:11AM +0300, Nir Soffer wrote:
> > On Tue, May 25, 2021 at 9:06 PM Richard W.M. Jones <rjones(a)redhat.com>
wrote:
> > > I ran perf as below. Although nbdcopy and nbdkit themselves do not
> > > require root (and usually should _not_ be run as root), in this case
> > > perf must be run as root, so everything has to be run as root.
> > >
> > > # perf record -a -g --call-graph=dwarf ./nbdkit -U - sparse-random
size=1T --run "MALLOC_CHECK_= ../libnbd/run nbdcopy \$uri \$uri"
> >
> > This uses 64 requests with a request size of 32m. In my tests using
> > --requests 16 --request-size 1048576 is faster. Did you try to profile
> > this?
>
> Interesting! No I didn't. In fact I just assumed that larger request
> sizes / number of parallel requests would be better.
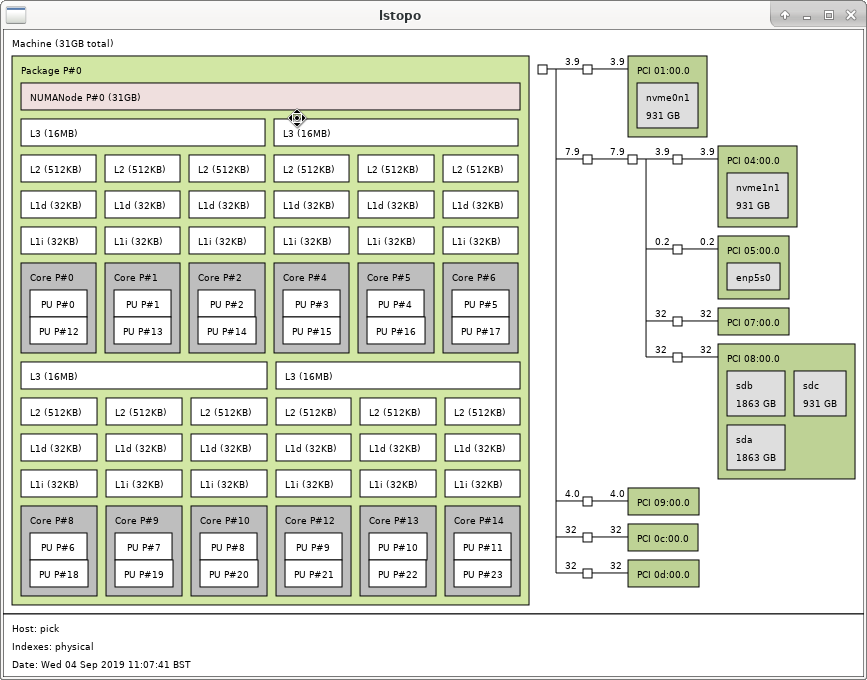
This is the topology of the machine I ran the tests on:
https://rwmj.files.wordpress.com/2019/09/screenshot_2019-09-04_11-08-41.png
Even a single 32MB buffer isn't going to fit in any cache, so reducing
buffer size should be a win, and once they are within the size of the
L3 cache, reusing buffers should also be a win.
That's the theory anyway ... Using --request-size=1048576 changes the
flamegraph quite dramatically (see new attachment).
Interestingly, now malloc is about 35% of the time (6.6/18.4) of the
worker thread.
{kind=link}
[What is the meaning of the swapper stack traces? They are coming
from idle cores?]
Test runs slightly faster:
$ hyperfine 'nbdkit -U - sparse-random size=1T --run "nbdcopy \$uri
\$uri"'
Benchmark #1: nbdkit -U - sparse-random size=1T --run "nbdcopy \$uri \$uri"
Time (mean ± σ): 47.407 s ± 0.953 s [User: 347.982 s, System: 276.220 s]
Range (min … max): 46.474 s … 49.373 s 10 runs
$ hyperfine 'nbdkit -U - sparse-random size=1T --run "nbdcopy
--request-size=1048576 \$uri \$uri"'
Benchmark #1: nbdkit -U - sparse-random size=1T --run "nbdcopy
--request-size=1048576 \$uri \$uri"
Time (mean ± σ): 43.796 s ± 0.799 s [User: 328.134 s, System: 252.775 s]
Range (min … max): 42.289 s … 44.917 s 10 runs
Adding --requests 16 is faster with real server, copying real images
and shared storage.
These flamegraphs are awesome!
Here are results from tests I did a few month ago in the RHV scale lab.
## Server
model name : Intel(R) Xeon(R) CPU E5-2630 v4 @ 2.20GHz
cores: 40
memory: 503g
## Source
Dell Express Flash PM1725b 3.2TB SFF
According to Dell site, this is:
http://image-us.samsung.com/SamsungUS/PIM/Samsung_1725b_Product.pdf
# qemu-img info /scratch/nsoffer-v2v.qcow2
image: /scratch/nsoffer-v2v.qcow2
file format: qcow2
virtual size: 100 GiB (107374182400 bytes)
disk size: 66.5 GiB
cluster_size: 65536
Format specific information:
compat: 1.1
compression type: zlib
lazy refcounts: false
refcount bits: 16
corrupt: false
Exported with qemu-nbd:
qemu-nbd --persistent --shared=8 --format=qcow2 --cache=none
--aio=native --read-only /scratch/nsoffer-v2v.qcow2 --socket
/tmp/src.sock
(Using configuration used by oVirt when exporting disks for backup)
## Destination
NetApp LUN connected via FC via 4 paths:
# multipath -ll
3600a098038304437415d4b6a59682f76 dm-4 NETAPP,LUN C-Mode
size=1.0T features='3 queue_if_no_path pg_init_retries 50'
hwhandler='1 alua' wp=rw
|-+- policy='service-time 0' prio=50 status=active
| |- 8:0:1:0 sdf 8:80 active ready running
| `- 8:0:0:0 sdd 8:48 active ready running
`-+- policy='service-time 0' prio=10 status=enabled
|- 1:0:0:0 sde 8:64 active ready running
`- 1:0:1:0 sdg 8:96 active ready running
Disk is a logical volume on this lun:
# qemu-img info -U
/dev/f7b5c299-df2a-42bc-85d7-b60027f14e00/8825cff6-a9ef-4f8a-b159-97d77e21cf03
image: /dev/f7b5c299-df2a-42bc-85d7-b60027f14e00/8825cff6-a9ef-4f8a-b159-97d77e21cf03
file format: qcow2
virtual size: 100 GiB (107374182400 bytes)
disk size: 0 B
cluster_size: 65536
Format specific information:
compat: 1.1
compression type: zlib
lazy refcounts: false
refcount bits: 16
corrupt: false
Exported with qemu-nbd:
qemu-nbd --persistent --shared=8 --format=qcow2 --cache=none
--aio=native /root/nsoffer/target-disk --socket /tmp/dst.sock
## Compare qemu-img convert, nbdcopy and libev-copy with similar
sparse settings.
Basically all give very similar results.
# hyperfine "./copy-libev $SRC $DST" "qemu-img convert -n -W -m 16 -S
1048576 $SRC $DST" "../copy/nbdcopy --sparse=1048576
--request-size=1048576 --flush --requests=16 --connections=1 $SRC
$DST"
Benchmark #1: ./copy-libev nbd+unix:///?socket=/tmp/src.sock
nbd+unix:///?socket=/tmp/dst.sock
Time (mean ± σ): 103.514 s ± 0.836 s [User: 7.153 s, System: 19.422 s]
Range (min … max): 102.265 s … 104.824 s 10 runs
Benchmark #2: qemu-img convert -n -W -m 16 -S 1048576
nbd+unix:///?socket=/tmp/src.sock nbd+unix:///?socket=/tmp/dst.sock
Time (mean ± σ): 103.104 s ± 0.899 s [User: 2.897 s, System: 25.204 s]
Range (min … max): 101.958 s … 104.499 s 10 runs
Benchmark #3: ../copy/nbdcopy --sparse=1048576 --request-size=1048576
--flush --requests=16 --connections=1
nbd+unix:///?socket=/tmp/src.sock nbd+unix:///?socket=/tmp/dst.sock
Time (mean ± σ): 104.085 s ± 0.977 s [User: 7.188 s, System: 19.965 s]
Range (min … max): 102.314 s … 105.153 s 10 runs
Summary
'qemu-img convert -n -W -m 16 -S 1048576
nbd+unix:///?socket=/tmp/src.sock nbd+unix:///?socket=/tmp/dst.sock'
ran
1.00 ± 0.01 times faster than './copy-libev
nbd+unix:///?socket=/tmp/src.sock nbd+unix:///?socket=/tmp/dst.sock'
1.01 ± 0.01 times faster than '../copy/nbdcopy --sparse=1048576
--request-size=1048576 --flush --requests=16 --connections=1
nbd+unix:///?socket=/tmp/src.sock nbd+unix:///?socket=/tmp/dst.sock'
## Compare nbdcopy request size with 16 requests and one connection
# hyperfine "./copy-libev nbd+unix:///?socket=/tmp/src.sock
nbd+unix:///?socket=/tmp/dst.sock"
Benchmark #1: ./copy-libev nbd+unix:///?socket=/tmp/src.sock
nbd+unix:///?socket=/tmp/dst.sock
Time (mean ± σ): 104.195 s ± 1.911 s [User: 8.652 s, System: 18.887 s]
Range (min … max): 102.474 s … 108.660 s 10 runs
# hyperfine -L r 524288,1048576,2097152 --export-json
nbdcopy-nbd-to-nbd-request-size.json "./nbdcopy --requests=16
--request-si
ze={r} nbd+unix:///?socket=/tmp/src.sock
nbd+unix:///?socket=/tmp/dst.sock"
Benchmark #1: ./nbdcopy --requests=16 --request-size=524288
nbd+unix:///?socket=/tmp/src.sock nbd+unix:///?socket=/tmp/dst.sock
Time (mean ± σ): 108.251 s ± 0.942 s [User: 5.538 s, System:
21.327 s]
Range (min … max): 107.098 s … 110.019 s 10 runs
Benchmark #2: ./nbdcopy --requests=16 --request-size=1048576
nbd+unix:///?socket=/tmp/src.sock nbd+unix:///?socket=/tmp/dst.sock
Time (mean ± σ): 105.973 s ± 0.732 s [User: 7.901 s, System:
22.064 s]
Range (min … max): 104.915 s … 107.003 s 10 runs
Benchmark #3: ./nbdcopy --requests=16 --request-size=2097152
nbd+unix:///?socket=/tmp/src.sock nbd+unix:///?socket=/tmp/dst.sock
Time (mean ± σ): 109.151 s ± 1.355 s [User: 9.898 s, System: 26.591 s]
Range (min … max): 107.168 s … 111.176 s 10 runs
Summary
'./nbdcopy --requests=16 --request-size=1048576
nbd+unix:///?socket=/tmp/src.sock nbd+unix:///?socket=/tmp/dst.sock'
ran
1.02 ± 0.01 times faster than './nbdcopy --requests=16
--request-size=524288 nbd+unix:///?socket=/tmp/src.sock
nbd+unix:///?socket=/tmp/dst.sock'
1.03 ± 0.01 times faster than './nbdcopy --requests=16
--request-size=2097152 nbd+unix:///?socket=/tmp/src.sock
nbd+unix:///?socket=/tmp/dst.sock'
## Compare number of requests with multiple connections
To enable multiple connections to the destination, I hacked nbdcopy to
ignore the the
destination can_multicon always use multiple connections. This is how we use
qemu-nbd with imageio in RHV.
This shows 10% better performance, best with 4 requests per connection, but
the difference between 4,8, and 16 is not significant.
# hyperfine -r3 -L r 1,2,4,8,16 "./nbdcopy --flush
--request-size=1048576 --requests={r} --connections=4
nbd+unix:///?socket=/tmp/src.sock nbd+unix:///?socket=/tmp/dst.sock"
Benchmark #1: ./nbdcopy --flush --request-size=1048576 --requests=1
--connections=4 nbd+unix:///?socket=/tmp/src.sock
nbd+unix:///?socket=/tmp/dst.sock
Time (mean ± σ): 117.876 s ± 1.612 s [User: 6.968 s, System: 23.676 s]
Range (min … max): 116.163 s … 119.363 s 3 runs
Benchmark #2: ./nbdcopy --flush --request-size=1048576 --requests=2
--connections=4 nbd+unix:///?socket=/tmp/src.sock
nbd+unix:///?socket=/tmp/dst.sock
Time (mean ± σ): 96.447 s ± 0.319 s [User: 8.216 s, System: 23.213 s]
Range (min … max): 96.192 s … 96.805 s 3 runs
Benchmark #3: ./nbdcopy --flush --request-size=1048576 --requests=4
--connections=4 nbd+unix:///?socket=/tmp/src.sock
nbd+unix:///?socket=/tmp/dst.sock
Time (mean ± σ): 91.356 s ± 0.339 s [User: 10.269 s, System: 23.029 s]
Range (min … max): 91.013 s … 91.691 s 3 runs
Benchmark #4: ./nbdcopy --flush --request-size=1048576 --requests=8
--connections=4 nbd+unix:///?socket=/tmp/src.sock
nbd+unix:///?socket=/tmp/dst.sock
Time (mean ± σ): 91.387 s ± 0.965 s [User: 12.699 s, System: 26.156 s]
Range (min … max): 90.786 s … 92.500 s 3 runs
Warning: Statistical outliers were detected. Consider re-running
this benchmark on a quiet PC without any interferences from other
programs. It might help to use the '--warmup' or '--prepare' options.
Benchmark #5: ./nbdcopy --flush --request-size=1048576 --requests=16
--connections=4 nbd+unix:///?socket=/tmp/src.sock
nbd+unix:///?socket=/tmp/dst.sock
Time (mean ± σ): 91.637 s ± 0.861 s [User: 13.816 s, System: 31.043 s]
Range (min … max): 91.077 s … 92.629 s 3 runs
Summary
'./nbdcopy --flush --request-size=1048576 --requests=4
--connections=4 nbd+unix:///?socket=/tmp/src.sock
nbd+unix:///?socket=/tmp/dst.sock' ran
1.00 ± 0.01 times faster than './nbdcopy --flush
--request-size=1048576 --requests=8 --connections=4
nbd+unix:///?socket=/tmp/src.sock nbd+unix:///?socket=/tmp/dst.sock'
1.00 ± 0.01 times faster than './nbdcopy --flush
--request-size=1048576 --requests=16 --connections=4
nbd+unix:///?socket=/tmp/src.sock nbd+unix:///?socket=/tmp/dst.sock'
1.06 ± 0.01 times faster than './nbdcopy --flush
--request-size=1048576 --requests=2 --connections=4
nbd+unix:///?socket=/tmp/src.sock nbd+unix:///?socket=/tmp/dst.sock'
1.29 ± 0.02 times faster than './nbdcopy --flush
--request-size=1048576 --requests=1 --connections=4
nbd+unix:///?socket=/tmp/src.sock nbd+unix:///?socket=/tmp/dst.sock'
Nir